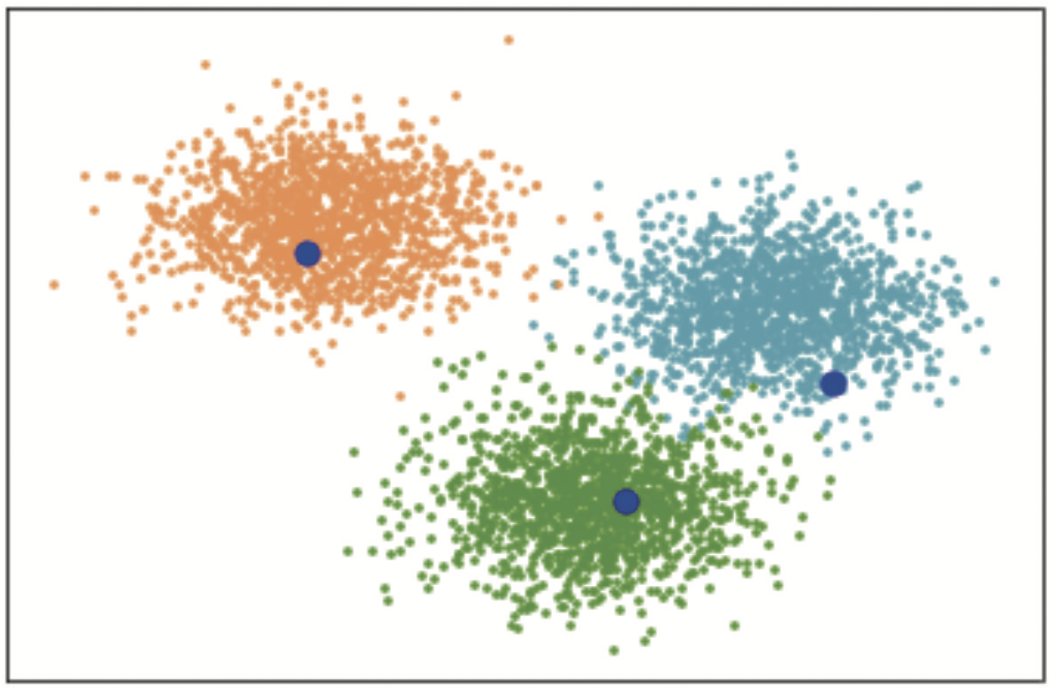
step1. 입력 데이터에서 k개의 군집 중심점을 임의로 선택한다. 세 개의 파란색 점이 임의로 주어진 초기 중심점이다. 초기 중심점의 개수는 k 값으로 지정한다.
step2. 모든 개별 입력 데이터와 K개 중심점과의 거리(유클리드 거리)를 계산한다. 계산 결과에 의해 개별 입력 데이터를 가장 가까운 중심점으로 소속시킨다. 이 과정을 통해 모든 데이터는 K개의 군집으로 소속이 정해진다.
step3. 군집별로 소속 데이터의 평균을 구해 이를 새로운 중심점으로 설정하여 K개의 새로운 군집 중심점을 정한다.
step4. 재조정된 중심점의 위치를 가지고 모든데이터에 대해 step2 부터 반복한다.
step5. 이 과정을 반복하다가 중심점의 위치가 수렴하면 과정을 끝낸다.
실습 해보기
from sklearn.cluster import KMeans # 사이킷런 라이브러리에서 KMeans를 불러오기
km = KMeans(n_clusters=3, random_state=0) # Kmeans 기능에서 군집 개수를 3개로 설정
df['cluster'] = km.fit_predict(df) # 데이터프레임 df를 군집분석한 결과로서 군집 결과값(레이블)을
df # cluster라는 변수명에 저장
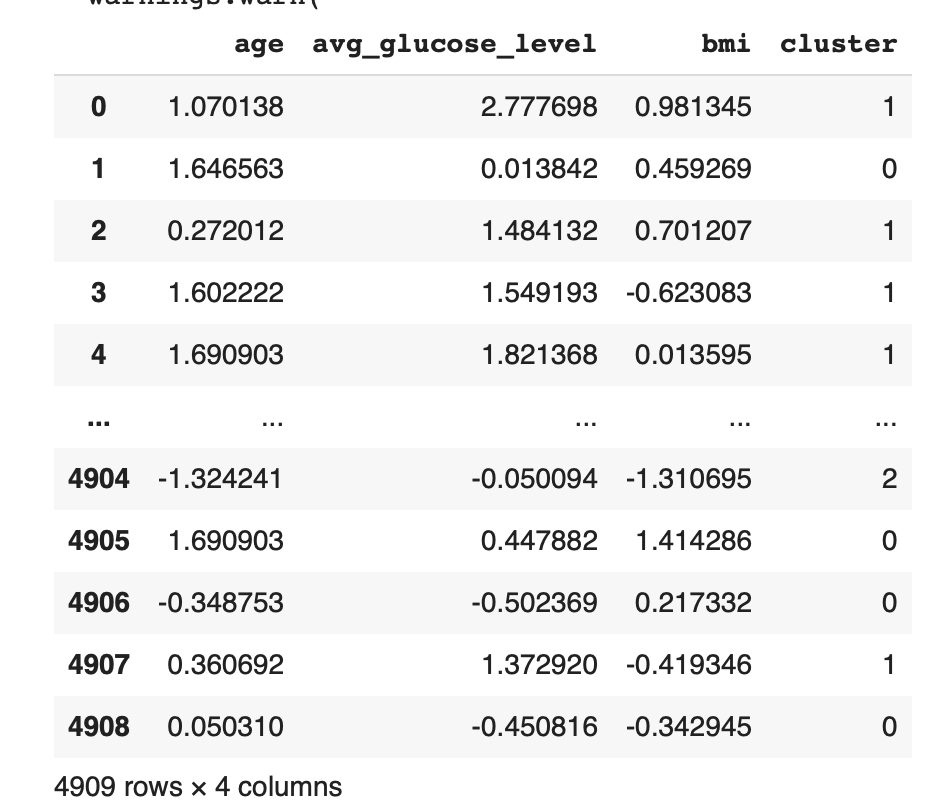
각 0,1,2 cluster 들이 나옵니다.
# 클러스터 레이블 별 colors를 다음과 같이 저장
# cluster0: 파랑, cluster1: 빨강, cluster2: 녹색
colors = ['b', 'r', 'g']
df['c'] = df['cluster'].map({0:colors[0], 1:colors[1], 2:colors[2]})
import matplotlib.pyplot as plt # matplotlib 라이브러리를 호출
# 그래프 그리기
fig, ax = plt.subplots(1, figsize=(8,8))
scatter = ax.scatter(df['age'],df['bmi'],c=df['c'], alpha = 0.6, s=10)
# 제목과 x축 y축 이름 설정
ax.set_title('K-Means Clustering')
ax.set_xlabel('age')
ax.set_ylabel('bmi');
### 아래 결과를 보면 빨강과 파랑 클러스터를 명확하게 구분할 수 없음에 유의
# 파랑 cluster0: 나이가 아주 어리지는 않은 그룹
# 빨강 cluster1: 나이가 아주 어리지는 않은 그룹
# 녹색 cluster2: 나이가 어리고 체질량이 작은 그룹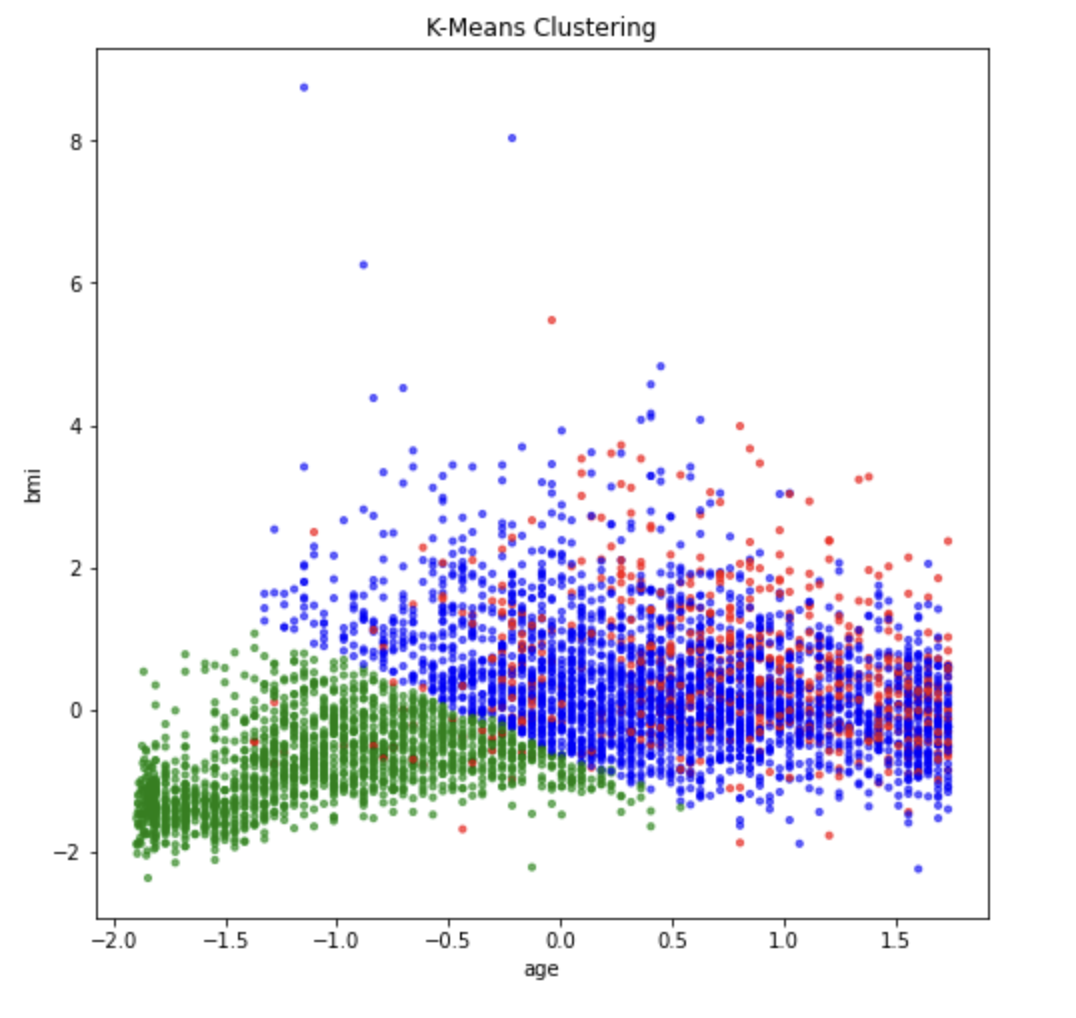
# 그래프 그리기
fig, ax = plt.subplots(1, figsize=(8,8))
scatter = ax.scatter(df['age'],df['avg_glucose_level'],c=df['c'], alpha = 0.6, s=10)
# 제목과 x축 y축 이름 설정
ax.set_title('K-Means Clustering')
ax.set_xlabel('age')
ax.set_ylabel('avg_glucose_level');
### 아래 결과를 보면 나이 및 혈당치로 클러스터를 명확하게 구분할 수 있
# 파랑 cluster0: 혈당량이 낮은 성인
# 빨강 cluster1: 혈당량이 높은 성인
# 녹색 cluster2: 어린이 및 청소년

'머신러닝' 카테고리의 다른 글
| 연관분석(Associations) (0) | 2024.06.10 |
|---|---|
| 결정트리 분류 모델 (0) | 2024.06.10 |
| Random Forest 모델 실습 (1) | 2024.06.10 |
댓글